PhD position (M2/école d'ingénieur.e.s)
posted on April 22, 2025
PhD position: Identification et commande de la boucle sensorimotrice de production de la voix parlée.
Deadline pour la candidature: 16 Mai 2025
Entretiens: 19-28 Mai 2025
Start date: 1er Octobre 2025
Durée: 3 ans
Le groupe Neuro du Département d’Automatique et Systèmes Micro-Mécatroniques, Institut FEMTO-ST à Besançon, France, cherche un.e candidat.e pour une thèse de doctorat à l’intersection entre l’instrumentation, de l’automatique et des neurosciences de la parole.
La thèse sera basée à l’Institut FEMTO-ST à Besançon et sera co-dirigée par Patrick Nectoux (Ingénieur de recherche CNRS en instrumentation/commande) et Jean-Julien Aucouturier (Directeur de recherche CNRS en sciences cognitives).
La thèse sera financée par une allocation de thèse ministérielle (MESRI), d’une durée de 3 ans à partir du 1er Octobre 2025, et encadrée par l’Ecole Doctorale Sciences Physiques pour l’Ingénieur et Microtechniques (ED37 SPIM), Université Marie et Louis Pasteur. Le salaire brut est de 2200€ mensuel (2300€ à partir de Jan. 2026).
Projet scientifique
Ce projet de thèse vise à développer de nouvelles techniques d’automatique (dispositif expérimentaux et algorithmes) avec pour objectif d’accroître notre compréhension d’une question neuroscientifique : comment l’homme contrôle le son de sa voix?
D’un point de vue neuroscientifique, la parole chez l’homme est rendue possible par une boucle de rétroaction sensorimotrice (« vocal feedback ») dans laquelle les locuteurs parlent, entendent ce qu’ils viennent de prononcer, et se corrigent si nécessaire. Ce système est très rapide et en grande partie automatique: par exemple, quand on s’entend parler avec un délai de quelques centaines de millisecondes, on ne peut s’empêcher de bégayer (Stuart et al., 2002); quand on modifie la voix du locuteur dans son casque de façon à en augmenter la hauteur (pitch), celui-ci ajuste automatiquement le pitch de sa voix vers le bas pour compenser, avec un délai d’environ 300 ms (Burnett, Senner & Larson, 1997).
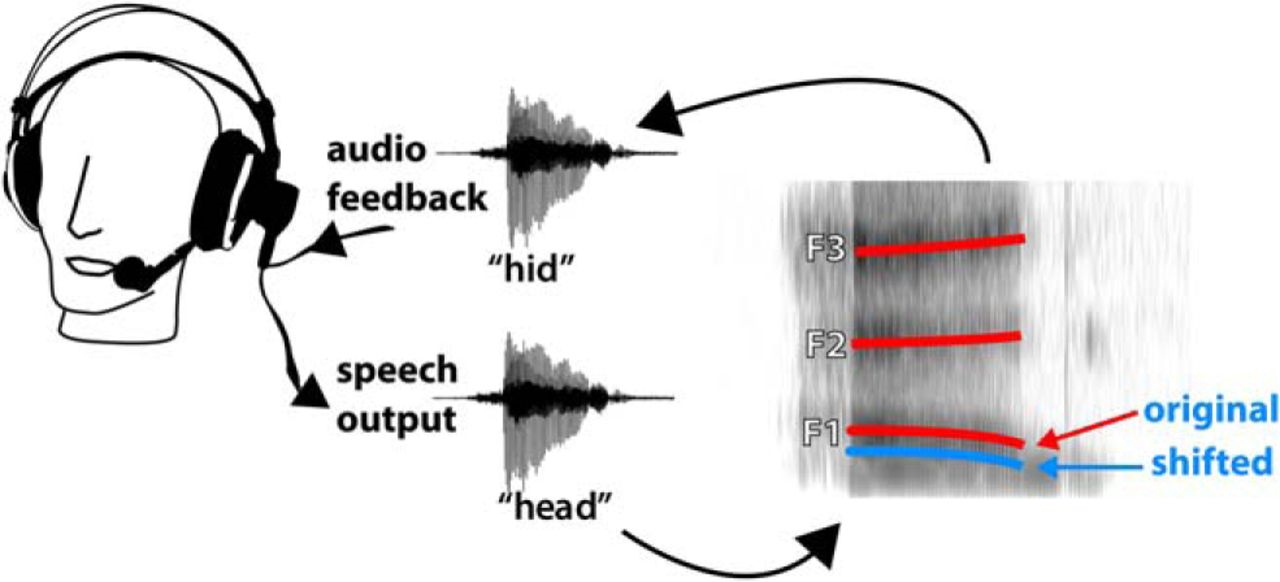
Ce phénomène fait l’objet de très nombreux travaux en neurosciences (y compris dans notre équipe : voir Aucouturier et al. 2016 ; Goupil et al. 2021). Ces travaux utilisent principalement la méthodologie « altered feedback » qui vise à introduire des perturbations de la voix perçue (ex. plus haute ou plus basse qu’elle n’a été produite) en quasi-temps-réel et en continu grâce à des algorithmes de traitement du signal, et d’en étudier l’effet sur la voix produite. Quoique ce système repose essentiellement sur une architecture boucle-fermée, elle a principalement été étudiée en boucle-ouverte (i.e. avec des manipulations de hauteur qui ne dépendent pas de la sortie observée du système), et la communauté semble être complètement passée à côté de l’aspect « automaticien » du problème : un seul article, marginal mais par une des équipes leader de la discipline (Guenther lab, Boston University), a proposé de faire de l’identification de paramètres d’un contrôleur PID, mais l’a fait en boucle ouverte (i.e. avec des données déjà collectées) et pour le comportement moyen d’un groupe (Kearney et al., 2022). Or, dans la pratique, la réponse individuelle de participants est très variable, à la fois entre participants et dans le temps au regard d’un même participant. Comprendre cette variabilité peut donner lieu à de grandes avancées théoriques (ex. de question : les bons chanteurs sont-ils de bons parleurs ?) et applicatives (ex. les paramètres du systèmes peuvent-ils être des biomarqueurs pour détecter ex. un Parkinson précoce ; Liu et al. 2012)
Projet de thèse
Le travail de thèse proposé consiste, d’une part, à développer un nouveau dispositif de feedback vocal temps-réel (développé sous LabVIEW sur cible CompactRIO/FPGA), permettant d’exécuter des algorithmes en temps déterministe (cad sans jitter) aussi bien en “hard” qu’en “soft”; et d’autre part, à l’utiliser expérimentalement pour réaliser la modélisation, l’identification et la commande du système sensorimoteur vocal au niveau de chaque participant individuellement.
L’identification fournira des paramètres qui seront testés comme possible biomarqueurs de différentes caractéristiques vocales des participants (ex. parole en langue maternelle vs en langue étrangère, en voix parlée vs chantée), et pourront également donner lieu à une application clinique dans le cadre de la maladie de Parkinson. La commande, cad la construction en temps-réel d’un signal de manipulation de la voix adaptée à la production de façon à en contrôler les caractéristiques, permettra de créer un système cyber-physique frappant (=faire chanter une personne à son insu, alors qu’elle croit maintenir une voix stable au casque), et ouvrir de possibles applications à des interventions thérapeutiques (ex. pour le bégaiement, ou les troubles du stress post-traumatique).
Le travail incluera à la fois de le développement d’un nouveau dispositif expérimental et d’algorithmes d’identification et commande, et leur mise en oeuvre expérimentale sur la personne humaine à la fois dans le cadre de notre propre laboratoire de neuroscience, mais aussi notre réseau de collaborateurs en neurosciences et sciences de la parole (Université de Lille, Université de Grenoble).
Profil de candidature
Ce projet de thèse sera adapté à un.e étudiant.e titulaire d’un M2 recherche et/ou d’un diplôme d’ingénieur.e avec un bon background en automatique (identification, commande boucle fermée, instrumentation), et/ou en traitement du signal (systèmes linéaires, signal sonore, temps-réel).
Les compétences techniques attendues sont la programmation Python (ex. analyse de données en pandas/seaborn) et LabVIEW (instrumentation, temps-réel). Une connaissance de l’environnement cRIO ou d’autres systèmes embarqués (arduino, etc.) pourra également être mise à profit. Enfin, une expérience ou un intérêt pour le logiciel libre, et le partage et la documentation de code sous git/github seront également appréciés. Les profils ne réunissant pas tous ces éléments sont évidemment les bienvenus, du moment que les candidat.e.s peuvent démontrer leur appétit d’apprendre.
Le projet étant à vocation expérimentale (développement de dispositif, expérimentation sur la personne humaine), le ou la candidate idéale aura une appétence pour l’expérimentation et le développement méthodologique, démontrée par exemple par une précédente expérience en stage de master. Enfin, l’application visée étant neuroscientifique, une expérience ou une formation complémentaire en sciences cognitives ou neurosciences sera un avantage apprécié – quoique non obligatoire.
Environnement
Le ou la doctorant.e rejoindra le groupe Neuro, une équipe de recherche qui réunit 2 chercheurs permanents, 1 chercheur postdoctorant et 4 doctorants, et dont les travaux de recherche explorent de nouvelles approches inspirées de l’automatique et des systèmes dynamiques pour les neurosciences (plus de détails). Le groupe Neuro est basé au Département d’Automatique et Systèmes Micro-Mécatroniques de l’Institut FEMTO-ST à Besançon, France, dans les locaux de l’école SUPMICROTECH/ENSMM.
Dans le groupe Neuro, le ou la doctorant.e sera co-dirigé.e par Patrick Nectoux (Ingénieur de recherche CNRS) et Jean-Julien Aucouturier (Directeur de recherche CNRS).
 Accueillant plus de 750 chercheurs, l’Institut FEMTO-ST (CNRS/Université Marie et Louis Pasteur) est l’un des plus gros laboratoire CNRS de France en Sciences de l’Ingénieur, avec une expertise couvrant l’ensemble des sciences de l’ingénieur et des systèmes. Le groupe Neuro est basé dans son Département d’Automatique et Systèmes Micro-Mécatroniques, qui accueille environ 80 chercheurs actifs dans les domaines de la robotique, de l’automatique, de la mécatronique et de l’intelligence artificielle.
Accueillant plus de 750 chercheurs, l’Institut FEMTO-ST (CNRS/Université Marie et Louis Pasteur) est l’un des plus gros laboratoire CNRS de France en Sciences de l’Ingénieur, avec une expertise couvrant l’ensemble des sciences de l’ingénieur et des systèmes. Le groupe Neuro est basé dans son Département d’Automatique et Systèmes Micro-Mécatroniques, qui accueille environ 80 chercheurs actifs dans les domaines de la robotique, de l’automatique, de la mécatronique et de l’intelligence artificielle.
 Classée au patrimoine mondial UNESCO, située à proximité des montagnes franco-suisses du Jura, la ville de Besançon est une capitale régionale à taille humaine, régulièrement primée pour sa qualité de vie et sa surface d’espace vert par habitant.
Classée au patrimoine mondial UNESCO, située à proximité des montagnes franco-suisses du Jura, la ville de Besançon est une capitale régionale à taille humaine, régulièrement primée pour sa qualité de vie et sa surface d’espace vert par habitant.
Comment candidater
Envoyer les élements suivants par email à Patrick Nectoux (patrick.nectoux@femto-st.fr) et Jean-Julien Aucouturier (aucouturier@gmail.com):
- un CV,
- une lettre de motivation (détaillant obligatoirement vos expériences répondant au paragraphe “profil de candidature” ci-dessus),
- une lettre de recommendation (professeur, tuteur de stage, etc.)
- relevé de notes et classement de M1, relevé de notes et classement de M2, si disponible
Date limite de candidature: 16 Mai 2025. Les candidat.e.s retenu.e.s sur la base de leur dossier seront convoqué.e.s pour un entretien (en présentiel ou sur zoom) la semaine du 19-28 Mai 2025, pour une décision finale prise avant le 31 Mai 2025.